Structuring Your Data Team: Unveiling Secrets — Tip #7
This is the first article about Team & Company. Let’s start with the making of a data team.
Team up
In #3 Finding Your Data Fit — 30 Tips to be Data Practitioners, I provided some ideas about how to determine your data stack based on your unique questions.
My experience is primarily with small startups where we had limited data team members and budgets. We mostly chose open-source tools like Airbyte, dbt, and Metabase — tools familiar to our data team members. We didn’t have the luxury 💸 of using Looker or Tableau.
Here is my v3.1:

Regarding team members, we didn’t hire new people. Instead, we positioned existing employees where they fit best. Compared to dbt’s What is Analytics Engineering in #5 Explore the Fancy Data World — 30 Tips to be Data Practitioners, one engineer, proficient in Python and JavaScript, and PM, me, took on the roles of Analytics Engineer and Data Analyst. Meanwhile, the consultant who created the dbt project performed the data engineer role.

We had discussions to define the roles and responsibilities within the data team, ensuring that the three of us understood how to collaborate effectively, what we delivered, and our individual contributions.
We didn’t require a full-time data engineer as we had few data sources and a relatively straightforward pipeline. The initial setup was more intensive, but maintenance required less effort.
Consider teaming up based on your data complexity, your employees, their skills and knowledge, and your goals for the data team. What challenges do you want your data team to address?👀
Building a data culture
Given the presence of data literacy and familiarity with spreadsheets in people’s daily lives, we believed that building a data team would reduce manual tasks so we aimed to connect every data source, hoping to extract maximum value from the collected data.
The founders and the data team shared this vision when we decided to form the team. Our goal was to offer data accessibility to everyone. With a strong foundation, the data team could empower colleagues to make data-informed decisions.
Successes
Effective setup + data catalog
We were fortunate to have a skilled consultant serve as our data engineer. It was his second time establishing a dbt project. Here’s his presentation from the Taipei dbt Meetup (in Chinese).
- dbt codegen for code generation, e.g., YML
- dbt-checkpoint provides pre-commit hooks to ensure the quality of your dbt projects.
- Check data source freshness
- Employ best practices with dbt-project-evaluator
- Define and monitor coding style using SQLFluff
- Synchronize documentation from dbt to Metabase using dbt-metabase
- Conduct model testing with dbt test
We adhered to dbt’s Best Practice Guides to structure our data models by source, both in staging and mart.
The setup process resembled reverse engineering to construct the data catalog. By documenting source data and transformed tables, it was the first time we gained clarity about our data. We discovered some misconceptions and myths about data sources. For instance, there were rumors about Table A being for users, but we actually had customer and user mappings spread across multiple tables.
Engaging early data users
We were elated when two data users built dashboards on Metabase even before we hosted our training session. Their initiative bolstered our confidence in fostering a self-service data culture.
Challenges
It’s not advisable to extract data from all sources initially. We ran out of time and had to focus on our primary production servers. Clarifying business logic, aligning metric definitions, and constructing transformed models for staging and marts consumed more time than anticipated. Plus, data users didn’t explore third-party data (like Zoom) as we’d hoped. Downloading CSV files from the Zoom backend sufficed. After a year, we disconnected from data sources for which we hadn’t built models.
Most colleagues weren’t early adopters. We had hoped they would be self-sufficient with data, but that wasn’t the case. I conducted a survey six months after the data pipeline was built. While the two adept data users who initially created dashboards impressed us, they represented a mere 2.5% of tech enthusiasts. Most data users were pragmatists seeking cleaner data, simpler usage methods, and easier access.
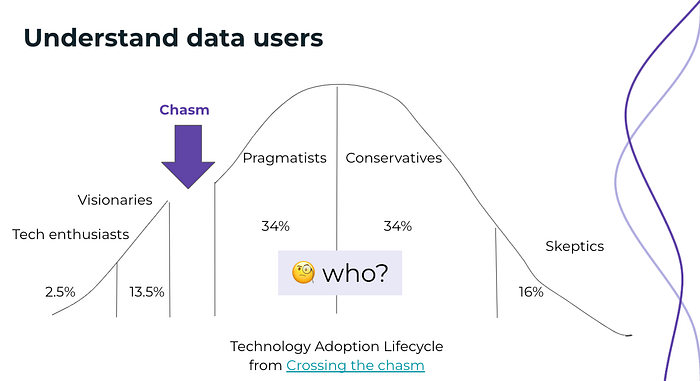
🗣️ Want to know more about the survey? Check my presentation about “How to build data accessibility for everyone” on Coalesce 2022.
The journey begins
We had an auspicious start as a data team. For the first time, we had a comprehensive list of all data sources and a clear data catalog. It was also the first time we agreed on a common start to the week: Monday (not Sunday). Such minor alignments proved to be essential.
This is just the beginning. Everyone was enthusiastic about launching a data team, centralizing data sources, and the possibility of discovering hidden insights.
In subsequent articles, I’ll guide you through the challenges I encountered. Hopefully, this will offer insights into potential pitfalls 🕳 for your data journey.
🤩 I’m happy to hear how you handle product development process? what tool do you use? Feel free to reach out to me on LinkedIn Karen Hsieh or Twitter @ijac_wei.
🙋🙋♀️ Welcome to Ask Me Anything.
