How to build data accessibility for everyone?
This article is the draft version for sharing in Coalesce 2022. Actually, the final version is >50% different from this one.
If you want to see the final version, check the video: https://www.youtube.com/watch?v=VMlrT4wXTgg
Data accessibility means the ability to access data.
Why do I promote “build data accessibility to everyone”?
🖼 Be data-informed
In a data-informed culture, we’ll let data act as a check on our intuition. e.g. If we know the reason behind the revenue increase is discount or profit, we will take different actions.
Few people can access data. They are the engineers who can access operating systems and the members of the data team. How can we be data-informed?

📍Self-served analysis is a must
We need to get data so we can check. There are 2 approaches,
- get data by requesting the data team
- get data without requesting the data team
When a data user wants to increase revenue, she wants to find opportunities by analyzing the data. In the 1st approach, the process is usually long and frustrating for both sides.
👩💼data user: Can you give me the revenue per month?
🏧 data team: Here you go. A csv or a spreadsheet.
👩💼data user: Can you break it down by channels?
🏧 data team: Here you go. Another csv.
The data team only gets the request instead of the real intention, finding opportunities to increase revenue. It’s hard for the data team to help, so they can only fulfill the request. The data user needs to wait for the data to discover, so her thinking pauses and resumes again and again. It’s not good for exploring insights.
Plus, the ratio of data team members and the data users may be 1:100. So for each data user, she may not feel like dealing with an ATM; She feels like dealing with a Complex Number Calculator.
Therefore, I like to go for the 2nd approach.
😵💫 Where to get data? — Data accessibility
“Get data without requesting the data team.” Where can we get data?

All data comes from the operating systems, e.g. logging data from the website users visited. Can we allow data users to access there since all data is there?
Well, 🫣 if you don’t care about stability. I had a funny experience. I didn’t know how to explain why I needed a data warehouse to the engineering team. Since the data was on S3, I wanted to access it, they set up Metabase, a BI tool, for me to get data. Then, whenever the website slowed down, they all looked at me: “Are you querying data?” 🤪
The database of the operating system is designed for operation, not for analytics.
Online Transaction Processing (OLTP) is very different from Online Analytical Processing (OLAP).
Cloud Data Warehouse Benchmark Redshift vs Snowflake vs BigQuery | Fivetran explains more details by George Fraser
OK, so don’t grant access to operating systems. We need a data warehouse. Can we allow data users to access the data warehouse?
Yes and No.
The source data that sync from operation systems and the transferred data transferred from the source data are stored in the data warehouse.
When I first got access to a data warehouse, it opened a new world indeed. Then I lost 😵.

I got lost in the source data. There was documentation but in the code, not on a written document. As a non-tech data user, I couldn’t understand the code. I queried DISTINCT the load_type and guess what each type meant. I checked to understand the relationships between different data tables. I asked a lot of questions.
It’s time for archeology 🔨. The worst part was that I documented my findings on my Notion so the documentation was outdated once any development changes. My documentation was not in the developing process. And the next data user needed to do what I had done again.
When I wrote a query, it was in the query editor on the data warehouse only. Therefore, I needed to write again if I wanted to get the same result but for the next month. Ends up, I saved many queries in my Notion 🤦♀️ again. It is hard to change and maintain, e.g. if the query to exclusive test users was changed, I needed to update many queries.
How about the transferred data? After I used dbt, I documented my archeology findings and modularized data models. It’s better. However, if we grant data users access to the data warehouse, we ask them to learn SQL and find a way to do reports. It’s a high bar for most data users, e.g. a marketer, a designer, or the HiPPO (Highest Paid People in the room)
Since transferred data is better, how about viewing it in a BI tool, where the data users can drag and drop what they want to see while checking the documentation?
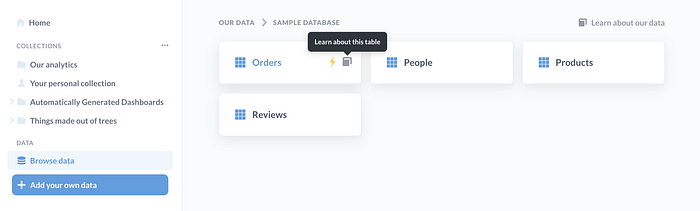
It looks promising 🤩. The bar is lower for the data users.
- The data users learn about the tables on the BI tool. The data is transferred so it’s more clean and easy to understand.
- The UI is friendly for non-tech people.
- They don’t need to learn SQL. If they do, they can use the advanced features.
So, we decided the transferred data and a BI tool are currently the best solutions.

Further reading, I recommend “The modern data experience” by Ben Stancil.
🐾 The stages and the challenges
Let’s go back to the beginning. In a data-informed culture, we like to empower data users to do self-serve analysis. It doesn’t start from self-serve. Most of the time, the data users are already self-serve by requesting data and analyzing it in spreadsheets.
1️⃣ The starting points
There are spreadsheets everywhere. There are spreadsheets for importing data, spreadsheets for calculating or adding some fact data manually, and spreadsheets for presenting the final data and charts. The entire ELT is in different spreadsheets. 😮
The challenges are
- Data transfer is unclear and misaligned. Too many spreadsheets are developed by different people, and the way they transfer data are not the same.
- It’s hard to check. You need to click the column of the spreadsheet to get the formula. And you need to ask why they write the formula in this way. There is no documentation.
- We don’t know all the spreadsheets. Many spreadsheets are in people’s private cloud storage. If they don’t share it with us, we won’t know.
🥊 How to start
Eat an elephant 🐘 one bite at a time.
The data team builds the ELT.
Start with 1 team as the first data users. Understand what they want to analyze and try to build 1 data model close to their business questions.
Though few sentences, many things need to accomplish. I use BQ + dbt + Metabase, for example.
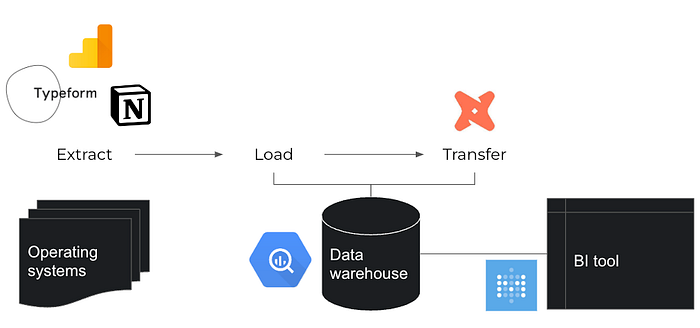
The archeology 🔨 work has to be done. Do it ONCE. Write the document in dbt, including the source data. Then the new members of the data team or data users outside the data team can know the data. The data team can see the DAG in dbt cloud, it’s easier to maintain the pipeline. The data users can view the description and get sample data on Metabase.
There are still detailed issues I want to have a better solution to:
- Visualize the relationships between source data tables. Cannot do that on dbt.
- How to write the document to a level that is simple but clear enough. e.g. there are 5 types of orders. Should I write the description of 5 types in the order_type description?
Some issues take times:
- The business definition is not clear enough. The data user who asks the data team to provide revenue reports, they don’t know there are details in the timezone, exchange rate, etc. Nor does the data team. Both sides are required to dive into the details.
- The business logic may be different from the technical logic. 1) The terms may be different. When the sales ask for a revenue report, they want to get the sum of all orders, which is with tax. When business owners ask for a revenue report, they are looking for revenue that can be realized, which is without tax. 2) The business logic may be missing from the technical logic. Say there are coupons sponsored by different partners, but there is no “sponsor” column in the data. When a BD wants to see how many coupons have been redeemed by partners, how can we provide that?
- The sense of the numbers. Take the sign-in rate of each sign-in option, for example. After the development of what to log, and how to calculate, we get 20% sign-in with Apple on Android phones and 15% sign-in with Apple on iOS phones. It doesn’t make sense for the data user but the data team may not discover it.
- No one can validate the accuracy without cross-checking. Of course, we do check, e.g. When we generate revenue reports from raw order data, we use them after code review and logic review. When we compare the revenue reports with the financial reports from the accounting system, we may find out the numbers are different due to the timezone, exchange rate, and tax. If we don’t compare, we will never know. And it comes to another question: Which one is correct?
There is a learning curve.
2️⃣ Shifting spreadsheets to the BI tool
We’ll hear a lot: “Why the number on Metabase is different from mine (spreadsheet)?”
People trust the data they produce. We need to earn the trust. I know it’s wired since the data team owns the source data, why do we need to convince people?
⚔️ PK time — Earn the trust
Data user owns the business logic. They have their ways of analyzing numbers. Data team converts the business logic into codes. There are many details while converting.
When a data user describes the business logic, he may lose some details. When an analytics engineer writes the code, his understanding may include assumptions. e.g. a data user asks for visited users per country. The business logic may be the users who visit the website by IP. The analytics engineer checks the registration country of each visited user. It’s natural to find a “country” column in the user table. They need to PK the data, and dive into why the numbers are different than the logic is aligned.
Even when the logic is the same. “Why the number on Metabase is different from mine (spreadsheet)?” OK. Can you give me your spreadsheet? Many times, the reason is different filtering. The data users must validate many times to be confident to throw the spreadsheets away.
The challenges continue:
- What level of transferred data is close enough to the data users? We hope the data users pick the data and get answered easily. We also don’t want to maintain >100 production data that are out of our control.
- Sometimes, we transfer data several times to the right level. What level should we materialize it? What data model should be stage or mart? How to manage?
- Is the business logic simple and focus enough? If 10 business owners view 10 different metrics, can these 10*10 requests be covered in ❤ production data?
- How to extend the DAG to dashboards? So we see the last miles to the data users.
A company with a few dashboards and a handful of key metrics can focus on what’s important; a company with hundreds can’t focus on anything. A data team that supports a small collection of production reports can keep them fresh and work on other projects; a data team with reports everywhere can’t do either.
from “If data is a product, what’s the production?” by Ben Stancil.
3️⃣ Onboard more data users
Once we get 1 team relying on the transferred data + BI tool, we like to onboard all teams so we have an SSOT, a single source of truth, in the entire company.
Introducing the data stack we use and the problems we like to resolve is not enough. People know something happened but do not get the impact. The dynamic dashboard on Metabase is the envy of other data users who crop and paste the charts from the spreadsheets.
Demo the first use case by the data users. It’s more powerful 📢 when the values of self-serve are shouted out by them.
- No “Your revenue is not my revenue.” When we say “revenue”, we are talking about the same thing.
- No spreadsheet with 25 tabs; Nor 25 spreadsheets for 1 report.
- Short feedback loop. Explore the data and get the answers right away.
- No repeat weekly, or monthly data work. The routine reports send out automatically.
Make these stages transparent. Discuss and retro how data users and data team co-work. We need to keep advocating. Each team has a learning curve.
🌱 Seed the data champions
Identify 1 person in each team who is interested in data. This person is the data champion who is curious about data and is excited to do self-serve. S/he will be the first one shifts her/his spreadsheet to the transferred data + BI tool.
But the challenges are non-stop:
- How to manage many dashboards created by many data users?
- How to encourage finding insights? We’d like to see data users exploring the data but also want to ensure they don’t misuse it.
- How can we build on top of what we know?
🙌 Raise the data literacy
When people access data to do self-serve analysis and build reports, their thoughts flow fast. The data team creates true value, empowering people to find insights. Both sides are happy.
When there are trusted data that can be accessed easily, everyone like to check the data. It reinforces the data-informed culture = raises company-wide data literacy.
🤩 I’m happy to hear from you. Feel free to reach out to me on LinkedIn Karen Hsieh or Twitter @ijac_wei.
🙋🙋♀️ Welcome to Ask Me Anything.
